

Googleの画像認識AI(Vision API)で、画像内のテキスト検出(OCR)した結果をテキストファイルにするには、text_detectionを使用します。
テキスト検出結果をテキストファイルにするには
入力画像・検出画像
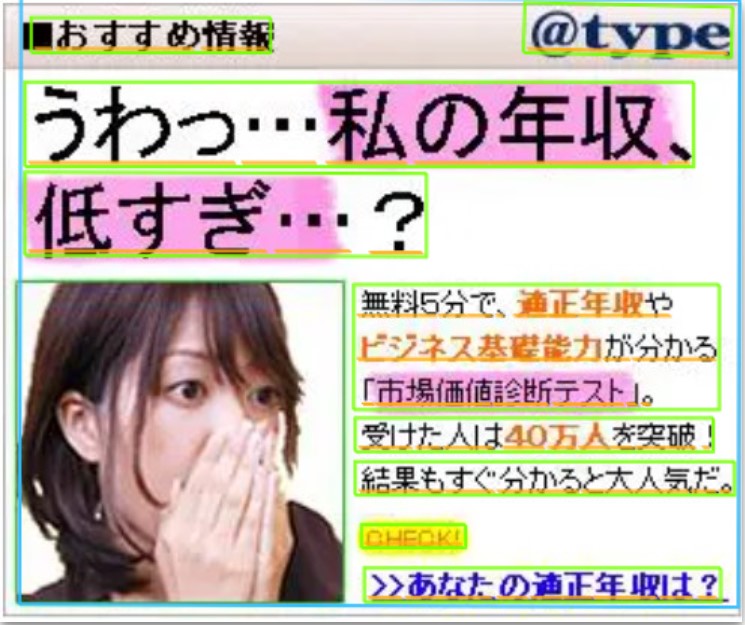
下の左側の有名な広告画像を、OCRでテキスト抽出してみます。
下の右側が、実際のCloud Vision APIでの検出画像です。

サンプルコード
実行する場合、APIキーファイルをGCPからダウンロードし、ファイル名をkey.jsonにして、サンプルコードと同じフォルダに格納してください。
from google.cloud import vision
from google.oauth2 import service_account
import io
# 身元証明書のjson読み込み
credentials = service_account.Credentials.from_service_account_file('key.json')
client = vision.ImageAnnotatorClient(credentials=credentials)
# ローカル画像を読み込み、imageオブジェクト作成
with io.open("./input.jpg", 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
# Cloud Vision APIにアクセスして、テキスト抽出結果を受け取る
response = client.text_detection(image=image)
# txtファイルに出力
f = open('output.txt', 'w', encoding='UTF-8')
f.write(response.text_annotations[0].description)
f.close()テキスト検出結果を、output.txtに出力しています。
実行結果(output.txtファイル)
おすすめ情報
@type
うわっ…私の年収、
低すぎ…?
無料5分で、適正年収や
ビジネス基礎能力が分かる
「市場価値診断デテスト」。
受けた人は40万人を突破!
結果もすぐ分かると大人気だ。
CHECK!
>>あなたの適正年収は?広告の文字列を、正確に検出できています。
関連記事
この記事は、Googleの画像認識AI(Vision API)でできることを一覧にした、逆引きリファレンスです。 物体検出 猫やベッドなどの、物体を検出するには 画像内の物体を検出するには、object_localizationを使用[…]
